|
I have generated a plot file (CSV with the locations of the plots for Collect Earth) with all of the sampling points for my survey. The file contains 10.000 plots now. When loading it through Collect Earth I have noticed that Google Earth has become very slow. Is this normal? Did I do something wrong? How do I fix this? /Question asked on behalf of a user |
|
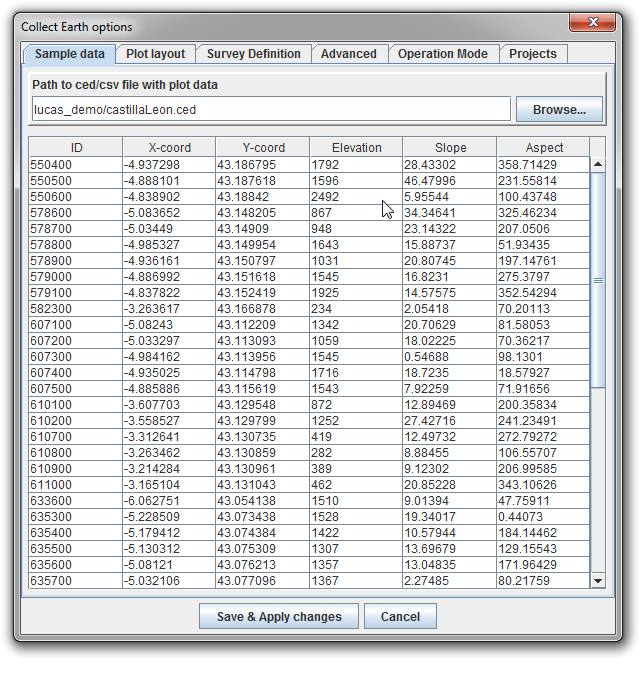
So this is really more of a Google Earth than Collect Earth problem. Collect Earth will take any plot location (CSV) file with the columns ID,latitude,longitude,... and from that it generates a KMZ file that is loaded in Google Earth ( you can find this KMZ file under the Collect earth data folder, on the generated folder e.g. : C:\Users\YOUR_USER\AppData\Roaming\CollectEarth\generated ) When Collect Earth is set to use a plot file with so many plots the file generated by Collect Earth becomes really big and difficult for Google earth to "swallow". We usually advise to use plot location files that have less then 5000 plots. So if you have plot locations over a whole country ( e.g. Spain ) you might just divide the plot locations by region or province so that you end up with much smaller plot files. For the data management, it does not matter where the plot locations come from, if they come from one or several folders is not an issue! So do not worry about dividing your plots amongst other files Then you will use the Tools->Properties in Collect Earth to switch provinces.
|
|
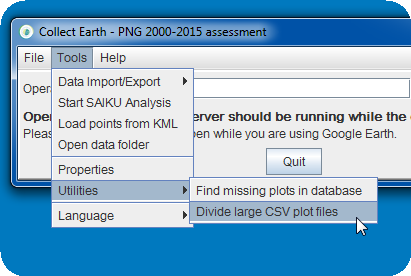
An update on this: We have now a utility inside Collect Earth (last version 1.5.7 ) that helps you in the process of chopping up a big CSV files into smaller ones!! It gives you the possiblity of randomizing the plots and also of dividing them using the values of one of the columns as the pivot. This is very useful if you want to divide the files into region/countries/etc... Go to Tools->Utilities->Divide large CSV plot files
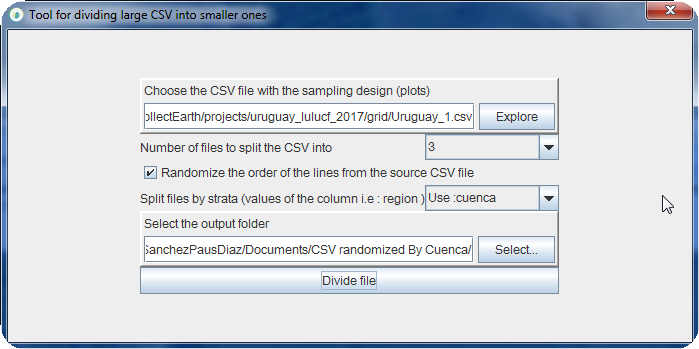
You can choose the number of files that you want to split the file into. If the order of the plots should be randomized so that interpreters get plots all over your area of interest, and, IF YOU ARE USING A CSV FOR THE SURVEY THAT IS LOADED then you can also choose one of the columns to generate strata-based sampling files.
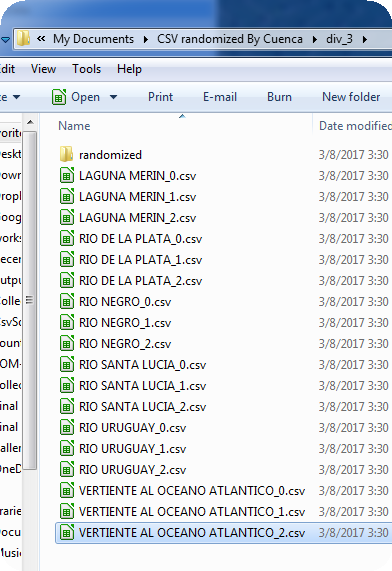
In this example we are "chopping" the CSV with plots from Uruguay. We specify that we want the order randomized and that it should be divided into THREE files. Note that we also say that we want to "split files by strata" using the Cuenca column of the CSV. This means that there will be three randomized files per strata! The resulting folder output will be divided into a folder with the plots NOT RANDOMIZED and another one with the same plots in a random order!!!
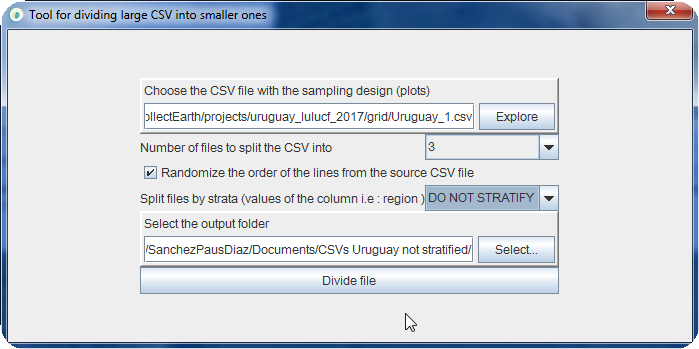
So if we had chosen the option to not Split the files by strata "DO NOT STRATIFY" then the result would have been :
|